Computer number format
A computer number format is the internal representation of numeric values in digital computer and calculator hardware and software.[1]
Contents |
Bits, bytes, nibbles, and unsigned integers
Bits
The concept of a bit can be understood as a value of either 1 or 0, on or off, yes or no, true or false, or encoded by a switch or toggle of some kind. A single bit must represent one of two states:
one-digit binary value: decimal value: ----------------------- -------------- 0 0 1 1 two distinct values
While a single bit, on its own, is able to represent only two values, a string of two bits together are able to represent twice as many values:
two-digit binary value: decimal value: ----------------------- -------------- 00 0 01 1 10 2 11 3 four distinct values
A series of three binary digits can likewise designate twice as many distinct values as the two-bit string.
three-digit binary value: decimal value: ------------------------- -------------- 000 0 001 1 010 2 011 3 100 4 101 5 110 6 111 7 eight distinct values
As the number of bits within a sequence goes up, the number of possible 0 and 1 combinations increases exponentially. The examples above show that a single bit allows only two value-combinations, while two bits combined can make four separate values; three bits yield eight possibilities, and the amount of possible combinations doubles with each binary digit added:
bits in series (b): number of possible values (N): ------------------------- ------------------------------ 1 2 2 4 3 8 4 16 5 32 6 64 7 128 8 256 ...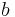
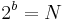
Bytes
A byte is often a computer's smallest addressable memory unit. In most computers this is an ordered sequence of eight bits or binary digits that can represent one of 256 possible values. Most recent computers process information in 8-bit units, or some other multiple thereof (such as 16, 32, or 64 bits) at a time. A group of 8 bits is now widely used as a fundamental unit, and is generally called a 'byte' (or sometimes octet).
Nibbles
In computing, a nibble (often nybble or even nyble to simulate the spelling of byte ) is a four-bit aggregation, or half an octet. As a nibble contains 4 bits, there are sixteen (24) possible values, so a nibble corresponds to a single hexadecimal digit (often referred to as a "hex digit").
Why binary?
- Computers use Boolean logic, which is a two-valued logic, and thus the two states of a binary system can relate directly to the two states of a Boolean logical system.
- It was easier to make hardware which can distinguish between two values than multiple values.
- Binary is slightly more efficient than decimal.[2] Many early computers used decimal (usually in binary-coded decimal representation). This approach was eventually largely abandoned due to the increase in processing circuitry, compared to binary.
- Other bases have been tried. A few experimental computers have been built with ternary (base 3) representation, as it was thought it might be more efficient than binary.[3]
Octal and hex number display
See also Base64.
Octal and hex are a convenient way to represent binary numbers, as used by computers. Computer mechanics often need to write out binary quantities, but in practice writing out a binary number such as 1001001101010001 is tedious, and prone to errors. Therefore, binary quantities are written in a base-8 ("octal") or, much more commonly, a base-16 ("hexadecimal" or "hex") number format.
In the decimal system, there are 10 digits (0 through 9) which combine to form numbers as follows:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ...
In an octal system, there are only 8 digits (0 through 7):
0 1 2 3 4 5 6 7 10 11 12 13 14 15 16 17 20 21 22 23 24 25 26 ...
That is, an octal "10" is the same as a decimal "8", an octal "20" is a decimal 16, and so on.
In a hex system, there are 16 digits (0 through 9 followed, by convention, with A through F):
0 1 2 3 4 5 6 7 8 9 A B C D E F 10 11 12 13 14 15 16 17 18 19 1A 1B...
That is, a hex "10" is the same as a decimal "16" and a hex "20" is the same as a decimal "32".
Converting between bases
Each of these number systems are positional systems, but while decimal weights are powers of 10, the octal weights are powers of 8 and the hex weights are powers of 16. To convert from hex or octal to decimal, for each digit one multiplies the value of the digit by the value of its position and then adds the results. For example:
octal 756 = (7 × 82) + (5 × 81) + (6 × 80) = (7 × 64) + (5 × 8) + (6 × 1) = 448 + 40 + 6 = decimal 494
hex 3b2 = (3 × 162) + (11 × 161) + (2 × 160) = (3 × 256) + (11 × 16) + (2 × 1) = 768 + 176 + 2 = decimal 946
Representing fractions in binary
Fixed-point numbers
Fixed-point formats are often used in business calculations (such as with spreadsheets or COBOL), where floating-point with insufficient precision is unacceptable when dealing with money. It is helpful to study it to see how fractions can be stored in binary.
A number of bits sufficient for the precision and range required must be chosen to store the fractional and integer parts of a number. For example, using a 32-bit format, 16 bits might be used for the integer and 16 for the fraction.
The fractional bits continue the pattern set by the integer bits: the eight's bit is followed by the four's bit, then the two's bit, then the one's bit, then of course the next bit is the half's bit, then the quarter's bit, then the ⅛'s bit, etc.
Examples:
integer bits fractional bits
0.5 = ½ = 00000000 00000000.10000000 00000000
1.25 = 1¼ = 00000000 00000001.01000000 00000000
7.375 = 7⅜ = 00000000 00000111.01100000 00000000
However, using this form of encoding means that some numbers cannot be represented in binary. For example, for the fraction 1/5 (in decimal, this is 0.2), the closest one can get is:
13107 / 65536 = 00000000 00000000.00110011 00110011 = 0.1999969... in decimal 13108 / 65536 = 00000000 00000000.00110011 00110100 = 0.2000122... in decimal
And even with more digits, an exact representation is impossible. Consider the number 1/3. If you were to write the number out as a decimal (0.333333...) it would continue indefinitely. If you were to stop at any point, the number written would not exactly represent the number 1/3.
The point is: some fractions cannot be expressed exactly in binary notation... not unless you use a special trick. The trick is, to store a fraction as two numbers, one for the numerator and one for the denominator, and then use arithmetic to add, subtract, multiply, and divide them. However, arithmetic will not let you do higher math (such as square roots) with fractions, nor will it help you if the lowest common denominator of two fractions is too big a number to handle. This is why there are advantages to using the fixed-point notation for fractional numbers.
Floating-point numbers
While both unsigned and signed integers are used in digital systems, even a 32-bit integer is not enough to handle all the range of numbers a calculator can handle, and that's not even including fractions. To approximate the greater range and precision of real numbers we have to abandon signed integers and fixed-point numbers and go to a "floating-point" format.
In the decimal system, we are familiar with floating-point numbers of the form:
- 1.1030402 × 105 = 1.1030402 × 100000 = 110304.02
or, more compactly:
1.1030402E5
which means "1.103402 times 1 followed by 5 zeroes". We have a certain numeric value (1.1030402) known as a "significand", multiplied by a power of 10 (E5, meaning 105 or 100,000), known as an "exponent". If we have a negative exponent, that means the number is multiplied by a 1 that many places to the right of the decimal point. For example:
- 2.3434E-6 = 2.3434 × 10-6 = 2.3434 × 0.000001 = 0.0000023434
The advantage of this scheme is that by using the exponent we can get a much wider range of numbers, even if the number of digits in the significand, or the "numeric precision", is much smaller than the range. Similar binary floating-point formats can be defined for computers. There are a number of such schemes, the most popular has been defined by Institute of Electrical and Electronics Engineers (IEEE). The IEEE 754-2008 standard specification defines a 64 bit floating-point format with:
- an 11-bit binary exponent, using "excess-1023" format. Excess-1023 means the exponent appears as an unsigned binary integer from 0 to 2047, and you have to subtract 1023 from it to get the actual signed value
- a 52-bit significand, also an unsigned binary number, defining a fractional value with a leading implied "1"
- a sign bit, giving the sign of the number.
Let's see what this format looks like by showing how such a number would be stored in 8 bytes of memory:
byte 0: S x10 x9 x8 x7 x6 x5 x4 byte 1: x3 x2 x1 x0 m51 m50 m49 m48 byte 2: m47 m46 m45 m44 m43 m42 m41 m40 byte 3: m39 m38 m37 m36 m35 m34 m33 m32 byte 4: m31 m30 m29 m28 m27 m26 m25 m24 byte 5: m23 m22 m21 m20 m19 m18 m17 m16 byte 6: m15 m14 m13 m12 m11 m10 m9 m8 byte 7: m7 m6 m5 m4 m3 m2 m1 m0
where "S" denotes the sign bit, "x" denotes an exponent bit, and "m" denotes a significand bit. Once the bits here have been extracted, they are converted with the computation:
- <sign> × (1 + <fractional significand>) × 2<exponent> - 1023
This scheme provides numbers valid out to about 15 decimal digits, with the following range of numbers:
| maximum | minimum | |
|---|---|---|
| positive | 1.797693134862231E+308 | 4.940656458412465E-324 |
| negative | -4.940656458412465E-324 | -1.797693134862231E+308 |
The spec also defines several special values that are not defined numbers, and are known as NaNs, for "Not A Number". These are used by programs to designate invalid operations and the like. You will rarely encounter them and NaNs will not be discussed further here. Some programs also use 32-bit floating-point numbers. The most common scheme uses a 23-bit significand with a sign bit, plus an 8-bit exponent in "excess-127" format, giving seven valid decimal digits.
byte 0: S x7 x6 x5 x4 x3 x2 x1 byte 1: x0 m22 m21 m20 m19 m18 m17 m16 byte 2: m15 m14 m13 m12 m11 m10 m9 m8 byte 3: m7 m6 m5 m4 m3 m2 m1 m0
The bits are converted to a numeric value with the computation:
- <sign> × (1 + <fractional significand>) × 2<exponent> - 127
leading to the following range of numbers:
| maximum | minimum | |
|---|---|---|
| positive | 3.402823E+38 | 2.802597E-45 |
| negative | -2.802597E-45 | -3.402823E+38 |
Such floating-point numbers are known as "reals" or "floats" in general, but with a number of inconsistent variations, depending on context:
A 32-bit float value is sometimes called a "real32" or a "single", meaning "single-precision floating-point value".
A 64-bit float is sometimes called a "real64" or a "double", meaning "double-precision floating-point value".
The term "real" without any elaboration generally means a 64-bit value, while the term "float" similarly generally means a 32-bit value.
Once again, remember that bits are bits. If you have eight bytes stored in computer memory, it might be a 64-bit real, two 32-bit reals, or four signed or unsigned integers, or some other kind of data that fits into eight bytes.
The only difference is how the computer interprets them. If the computer stored four unsigned integers and then read them back from memory as a 64-bit real, it almost always would be a perfectly valid real number, though it would be junk data.
So now our computer can handle positive and negative numbers with fractional parts. However, even with floating-point numbers you run into some of the same problems that you did with integers:
- As with integers, you only have a finite range of values to deal with. Granted, it is a much bigger range of values than even a 32-bit integer, but if you keep multiplying numbers you'll eventually get one bigger than the real value can hold and have a numeric overflow. If you keep dividing you'll eventually get one with a negative exponent too big for the real value to hold and have a numeric underflow. Remember that a negative exponent gives the number of places to the right of the decimal point and means a really small number. The maximum real value is sometimes called "machine infinity", since that's the biggest value the computer can wrap its little silicon brain around.
- A related problem is that you have only limited "precision" as well. That is, you can only represent 15 decimal digits with a 64-bit real. If the result of a multiply or a divide has more digits than that, they're just dropped and the computer doesn't inform you of an error. This means that if you add a very small number to a very large one, the result is just the large one. The small number was too small to even show up in 15 or 16 digits of resolution, and the computer effectively discards it. If you are performing computations and you start getting really insane answers from things that normally work, you may need to check the range of your data. It is possible to "scale" the values to get more accurate results. It also means that if you do floating-point computations, there's likely to be a small error in the result since some lower digits have been dropped. This effect is unnoticeable in most cases, but if you do some math analysis that requires lots of computations, the errors tend to build up and can throw off the results. The fraction of people who use computers for doing math understand these errors very well, and have methods for minimizing the effects of such errors, as well as for estimating how big the errors are. By the way, this "precision" problem is not the same as the "range" problem at the top of this list. The range issue deals with the maximum size of the exponent, while the precision issue deals with the number of digits that can fit into the significand.
- Another more obscure error that creeps in with floating-point numbers is the fact that the significand is expressed as a binary fraction that doesn't necessarily perfectly match a decimal fraction. That is, if you want to do a computation on a decimal fraction that is a neat sum of reciprocal powers of two, such as 0.75, the binary number that represents this fraction will be 0.11, or ½ + ¼, and all will be fine. Unfortunately, in many cases you can't get a sum of these "reciprocal powers of 2" that precisely matches a specific decimal fraction, and the results of computations will be very slightly off, way down in the very small parts of a fraction. For example, the decimal fraction "0.1" is equivalent to an infinitely repeating binary fraction: 0.000110011 ...
Numbers in programming languages
Low-level programmers have to worry about unsigned and signed, fixed and floating-point numbers. They have to write extremely different code, with different opcodes and operands, to add two floating point numbers compared to the code to add two integers.
However, high-level programming languages such as LISP and Python offer an abstract number that may be an expanded type such as rational, bignum, or complex. Programmers in LISP or Python (among others) have some assurance that their program code will Do The Right Thing with mathematical operations. Due to operator overloading, mathematical operations on any number—whether signed, unsigned, rational, floating-point, fixed-point, integral, or complex—are written exactly the same way. Others languages, such as REXX and Java, provide decimal floating-points, which avoids many "unexpected" results. One drawback in Java though, is its lack of native support for unsigned integer types.
See also
Notes and references
The initial version of this article was based on a public domain article from Greg Goebel's Vectorsite.
- ^ Jon Stokes (2007). Inside the machine: an illustrated introduction to microprocessors and computer architecture. No Starch Press. p. 66. ISBN 9781593271046. http://books.google.com/books?id=Q1zSIarI8xoC&pg=PA66.
- ^ Amdahl, G.M., Blaauw, G.A., and Brooks, FP (1964). "Architecture of the IBM System/360". IBM Journal of Research and Development 8 (2): 87–101. http://books.google.com/books?id=I7o8teBhz5wC&pg=PA26.
- ^ The number of possible symbols needed to represent a range of numbers is most often minimal for base 3, although binary is close in this measure. Since no substantial advantage emerged from this fact, use of base 3 for computers has not been actively pursued. See Brian Hayes, "Third Base", American Scientist 89(6): 490–494 (2001), [1].